{kind=link}
Welcome to this page. I am going to provide you with the operational characteristics of Cybele Unbound and some useful information about testing procedures of expert advisors. I hope you will find the information provided on this page useful and productive for your future endeavors with our as well as other expert advisors.
I am a 44 year old PhD graduate proprietary trader. I am mainly trading index futures. My trading history goes back to the 1990s when I was in high school where we send our quotes by phone and watch the prices trough teletext system in our CRT TVs (Cathode Ray Tube TVs)
I met with algorithmic trading in the 2010s. At those times, without any exception all algorithms were just crap. After blowing several accounts with expert algorithms, I decided to close the book of algorithmic trading for another next 10 years.
Trading is a job field where you make money by only “sitting”. As your trading evolves and your eyes are trained, then you start to pick only A++ quality trades. It turns out that I have been spending most of my days by only ‘sitting’. Having redundant of spare time, I decided to develop my trading algorithm that mimics the behavioral characteristics of my manual trading principles.
That was the time when Institution Breaker and Cybele were born.
3- Distinguishing Characteristics of Cybele Unbound
Cybele Unbound is an AI-powered quant trading bot based on price action and probability theories, utilizing institutional trading strategies. It continuously adapts to changing market conditions and employs strict risk management methods.
What sets this EA apart is the use of probability theory into the trade decisions. This is made possible by its use of a complex machine learning algorithm, enabling the advisor to compute the percentile of the current price.
Utilizing this approach we could eliminate bad quality trades and take only A++ quality ones that have the highest probability of winning. This learning capability also ensures Cybele Unbound to stay in tune with various market scenarios.
4- How Probability Models Evolved With Artificial Intelligence?
The AI revolution is dramatically changing the landscape of stock trading, and one area that has been profoundly affected is probability theory—the foundation for risk assessment, prediction, and decision-making in the financial markets.
1. Enhanced Data Processing and Pattern Recognition
Traditional stock trading models relied on historical data and standard probability theory to predict future market movements. Traders would use statistical methods to calculate probabilities based on past patterns, such as price movement and volatility. However, the AI revolution has transformed this process by enabling machines to process vast amounts of data at speeds humans cannot match.
AI systems, particularly machine learning algorithms, now analyze not only historical price data but also incorporate other variables like social media sentiment, news events, and macroeconomic data. This has added complexity to traditional probability models, as machines can detect non-linear relationships and hidden patterns that were previously unseen, thus altering the probabilities assigned to certain outcomes. The result is more accurate predictions and a redefinition of risk probabilities in stock trading.
2. Dynamic Adjustment of Probabilities
In classical probability theory, stock market models often assume that price movements follow a random walk, implying that future prices are independent of past prices, and the probability of an outcome is relatively fixed. With AI, this assumption has been re-evaluated. AI algorithms adjust probabilities dynamically, learning from every new data point. This continuous learning process allows machines to update the probability of an event in real-time based on changing market conditions, significantly improving the accuracy of short-term trading predictions.
For instance, if a news event occurs that changes market sentiment, AI can immediately adjust the probability of a price increase or decrease, making decisions more responsive to new information and improving real-time market efficiency.
3. Improved Risk Management
AI is also reshaping how probability theory is used in risk management. By combining vast data sets with sophisticated algorithms, AI tools are more adept at identifying rare market events or “black swan” events, which are often poorly handled by traditional models that assume a normal distribution of returns. This has led to the development of probabilistic risk models that better account for extreme events and tail risks.
AI-based systems now provide traders with more realistic probability estimates for rare events, allowing for better risk-adjusted returns. In other words, AI is improving the precision of calculating probabilities in tail-risk scenarios, leading to more robust hedging strategies and risk mitigation.
4. Probabilistic Trading Strategies
The rise of algorithmic trading powered by AI has also led to the adoption of probabilistic trading strategies, where traders use AI to determine the probability of success for each trade. Rather than relying on a fixed strategy, these AI-driven systems assign probabilities to various outcomes based on continuous data analysis and automatically execute trades with the highest expected probability of success.
For example, AI can predict the likelihood that a certain stock will hit a target price based on thousands of variables, enabling traders to make more informed decisions. This probabilistic approach moves away from deterministic, rule-based strategies and leverages AI’s ability to optimize trading based on real-time data and probabilities.
In conclusion, the AI revolution has fundamentally shifted how probability theory is applied in stock trading. AI’s ability to process enormous datasets, dynamically adjust probabilities, and refine risk management has revolutionized market predictions and trading strategies. As AI continues to evolve, its impact on probabilistic decision-making in stock trading will likely deepen, making it an indispensable tool for traders aiming to navigate the complexities of modern financial markets.
5- How Cybele Use Probability Theory and AI Together?
In trading, probability and percentile theories are essential tools for assessing market conditions and managing risk. It is very new in MQL5 world and as far as we know, Cybele Unbound is the only expert advisor that relies on this principle.
Probability theory helps traders estimate the likelihood of specific outcomes, such as price movements or trend continuations, allowing for more informed decision-making. By analyzing historical data and price patterns, Cybele Unbound can assign probabilities to future events and craft strategies with higher chances of success.
Percentile theory complements this by offering a way to evaluate an asset’s performance relative to historical benchmarks. For example, the expert advisor uses percentiles to identify whether current prices or market conditions fall within extreme ranges, helping to determine overbought or oversold scenarios. Together, these theories empower the Cybele Unbound to approach the markets with a more structured, statistical mindset, enhancing both risk management and profit potential.
6- How Cybele Unbound Was Developed: The Extreme Approach
There are 2 key terms we should be aware of: The data fitting and population generation models. Before developing a model, developers have to choose one of these methods.
In the data fitting approach, a model is pushed to fit the past data. Because you can make any trading model to fit to the past data, such algorithms are not reliable. The truth is, you can show any trading model as if it performs perfectly well and perfectly profitable with optimization. As I stated at the beginning, this was the dominant approach in the 2010s and without exception all EAs were nothing but crap.
In the second approach, you would want to generate a mathematical model that mimics the behavioral characteristics of the original data generating process. You can think of this like an imitation of a reality.
For example, there is an interaction every millisecond in the Nasdaq stock exchange that produces those graphical representations among market participants, namely buyers and sellers. We see this interaction in the form of graphical representation of price changes. In a population generating model, you basically develop a model that behaves like an imitation of Nasdaq.
Because you are working on the real data generation process itself, these models are reliable.
When you develop a model that you think is a good imitation, THEN, you apply it to the data and see how it behaves.
7- Beating Backtest Pitfalls With Using Quality data and Second Simulator
In the world of Meta Quotes, brokers deal with the past data in two ways: either they store their own data or they use Meta Quotes servers. On the other hand, Meta Quotes do not store the 100% of real ticks, it uses sort of smoothed ticks that occupy much less space.

The truth is, most brokers do not store the data in their own servers. When you test the model with past data, they call the data from the servers of Meta Quotes. Therefore, you test the model with this smoothed data. Of course when you test a model with smoothed data, you actually don’t test it properly simply because the data is not a good representation of the real world. In this case your results would not be reliable.
Meta Quotes’ trading platform, Meta Trader is also continuously updating and after every update some algorithmic changes are applied. Even if you test the model with the same data, results can vary between 2 meta trader versions.
These are the pitfalls of standard testing procedures that many retail traders use everyday. To overcome these pitfalls, we test our models with Ducascopy data. Ducascopy has its own data servers and stores the data independent from Meta Quotes. Therefore, Cybele Unbound is tested using 99.9% of real ticks of Ducascopy data.
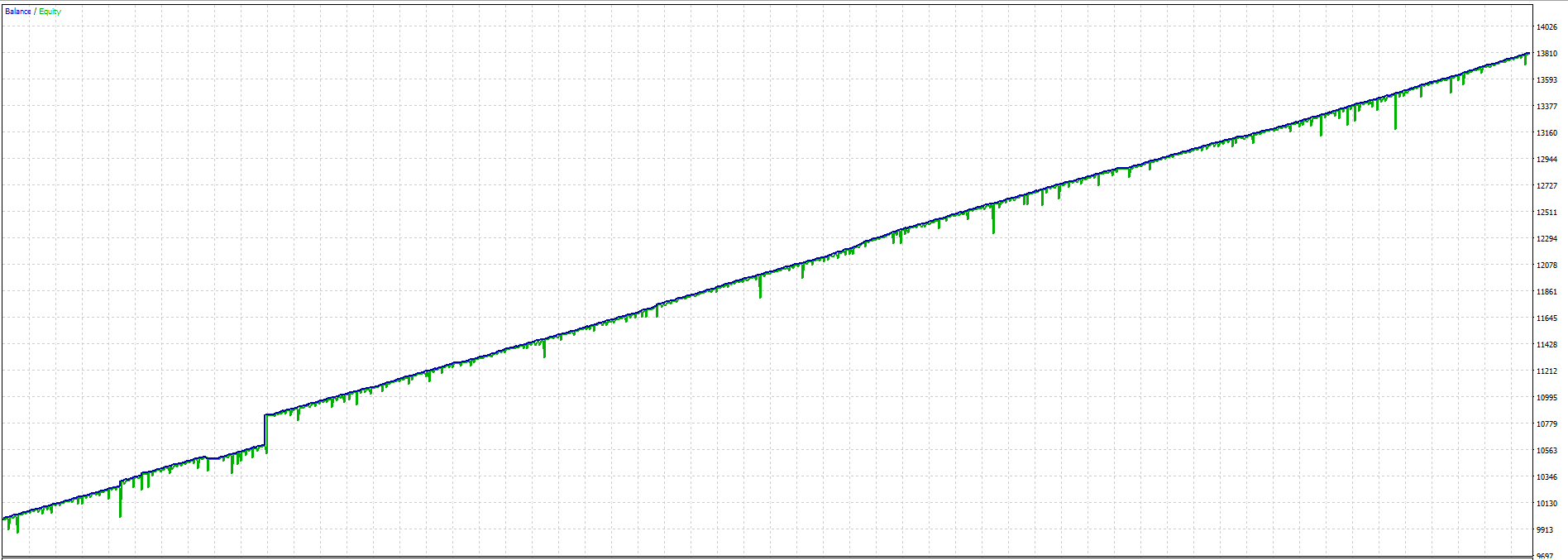
8 – Gird System and the Results
In the backtest, we consider 2018+ . Because Cybele Unbound is not a history reader, there is no point to go more than that. Indeed, in any bot, when the algorithm is good you really do not need to go beyond 2 -3 years of backtest. Because market dynamics always change and not stable – the market condition 10 year ago is not same as it was 5 years ago, 2 years ago etc. That is, the the algorithm just can not learn the pricing dynamics of the market 10 years ago and those 5 years ago at the same time. It need to be re-optimized.
We also added a simple grid mechanisms on top of the core algorithm to enhance results. Here are the results with and without grid:
CYBELE UNBOUND 0.1 LOT WITH GRID OFF: $3804 PROFIT – $278 MAX EQUITY DD